
According to Deloitte’s The State of AI in 2026 report, 74% of companies plan to deploy agentic AI within two years. Yet only 21% report having a mature governance model for autonomous agents. The problem is crystal clear: Enterprises are rushing toward automation without a structured AI agent architecture to guide them.
An AI system architecture directly impacts your business. Therefore, having a layered, modular AI agent architecture is indispensable. It defines how systems handle scale, complexity, and reliability. It ensures that your AI agent works as intended in production and supports long-term growth.
Here’s a quick look at how a production-grade AI agent system design can impact your business:
- Faster issue resolution
- Controlled infrastructure costs
- Reduced operational disruptions
- Reliable system performance at scale
- Stronger data security and compliance
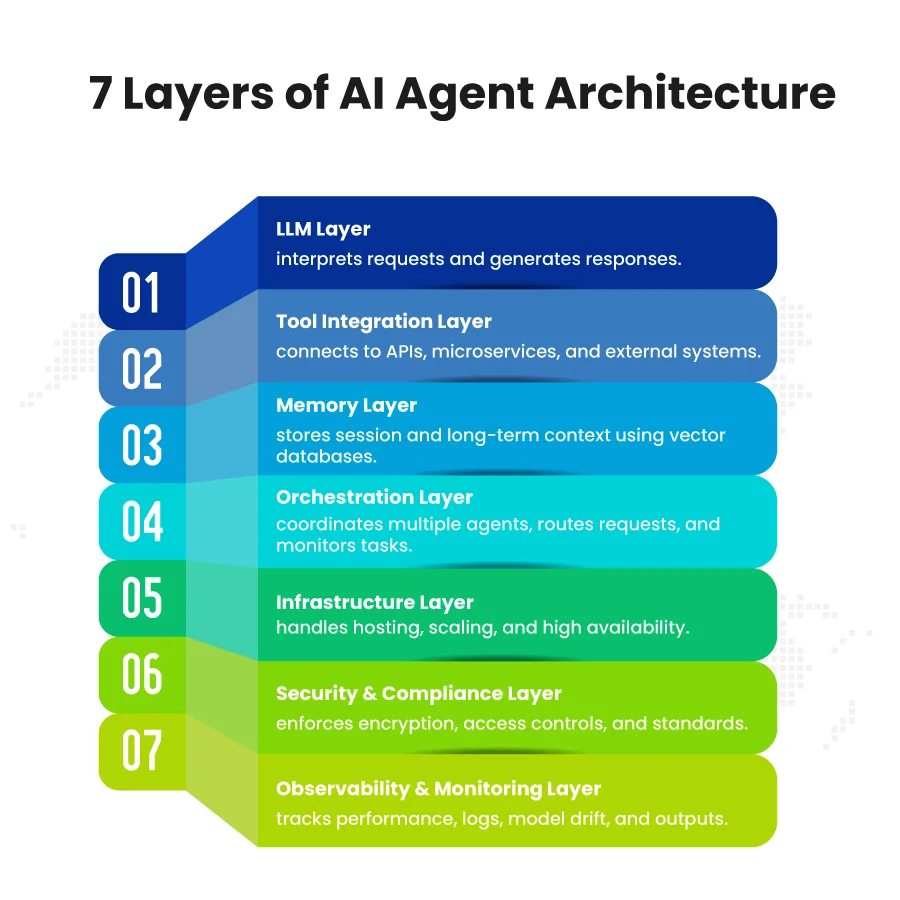
If you want to achieve these business objectives, you must understand each of the seven layers of an AI agent architecture, from the LLM layer to the observability layer.
In this guide, we’ve shared a realistic AI agent architecture blueprint. This framework will help you design scalable AI infrastructure, deploy production-ready AI agents, and build an AI agent stack that works reliably in real-world business settings.
How Does AI Agent Architecture Work?
Before diving into the layers, first, let’s understand how the AI agent system architecture functions as a cohesive structure. Each layer works together to process data, coordinate tasks, and deliver reliable outputs, ensuring the system can scale and remain secure.
1. Understanding and Generating Outputs
Everything starts with the LLM layer, where the agent interprets requests and generates intelligent responses. The model decides what to do based on context from memory and the tools it has access to.
2. Bringing Tools and External Data Into Play
Next, the Tool Integration Layer connects the agent to APIs, microservices, and enterprise applications. This is where external knowledge or actions come into the system. This layer ensures the agent can interact safely and reliably with other systems, enabling it to perform real-world tasks beyond raw text generation.
Table of Contents
3. Remembering Context and Knowledge
The Memory Layer captures everything the agent needs to recall, from session context to long-term information stored in vector databases like Pinecone, FAISS, or Weaviate. Using embeddings and RAG architecture, it allows the agent to respond with awareness of past interactions and relevant data.
4. Orchestrating Tasks Across Agents
The Orchestration Layer ensures that when multiple agents are running, their tasks don’t collide. It routes requests, monitors progress, and coordinates outputs, forming the backbone of a multi-agent system architecture.
5. Supporting Everything with Robust Infrastructure
All of this runs on the infrastructure layer, which hosts the system on Kubernetes, serverless platforms, or hybrid environments. This layer handles scaling, resource allocation, and high availability, so the agent can operate continuously.
6. Keeping the System Secure and Compliant
The Security & Compliance Layer wraps the core layers. It enforces encryption, access controls, and standards like GDPR or SOC 2. It protects against attacks, data leaks, or model tampering, ensuring the architecture remains trustworthy and enterprise-ready.
7. Observing and Adjusting in Real Time
Finally, the Observability & Monitoring Layer watches everything: performance, logs, model drift, and prompt outputs. It provides the feedback needed to adjust workflows, optimize scaling, and maintain consistent, predictable behavior.
In the next sections, we’ll discuss each layer of AI agent architecture in detail.
1. LLM Layer – The Brain of Your AI Agent
The LLM layer is where your AI agent thinks, reasons, and generates responses. Memory, tools, and orchestration all revolve around it. If this layer is misaligned with product goals, no infrastructure upgrade will compensate for it.
In real-world AI agent production deployment, many breakdowns trace back to poor model fit. The wrong model quietly compounds errors at every step.
To get this right, CTOs need to understand key decisions around model selection, deployment approach, and context management.
Defining Model Requirements
Before choosing between large language models (LLMs) such as the OpenAI API, Anthropic Claude, Google Gemini, Azure OpenAI, or AWS Bedrock, clarify what the agent is actually expected to handle.
Is it structured document analysis? Multi-step reasoning across tools? Or high-volume conversational workflows?
A disciplined model selection strategy should evaluate the following:
- Task complexity and reasoning depth
- Data sensitivity and compliance exposure
- Latency under expected traffic conditions
Model latency considerations often surface only after launch. What works in controlled tests may struggle once concurrency rises.
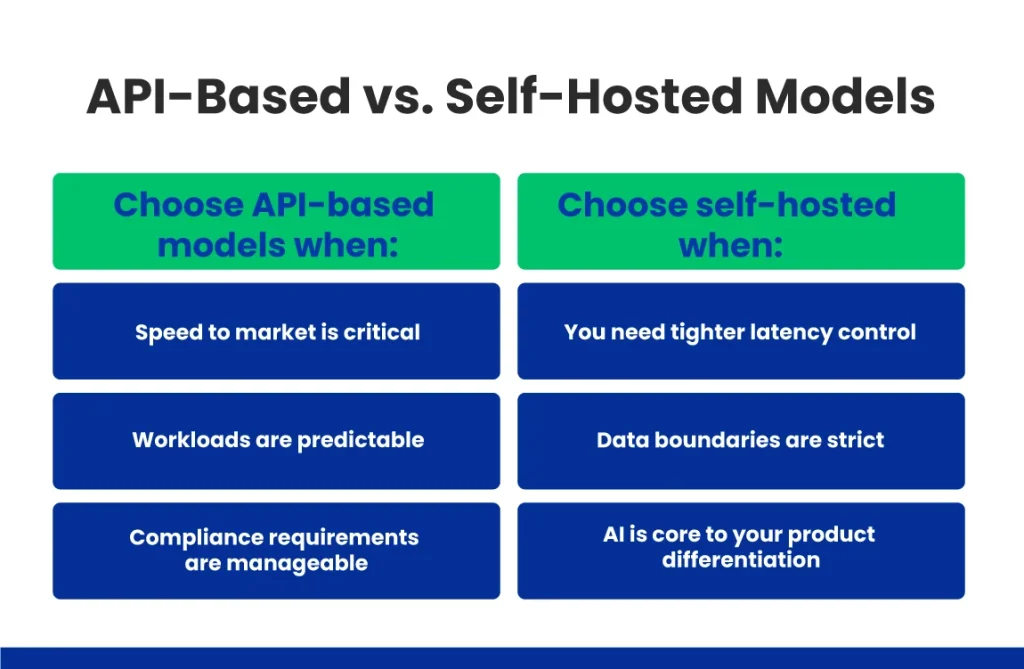
Choosing Between API-Based vs. Self-Hosted Models
The API-based vs. self-hosted LLM decision affects your broader AI backend architecture. An API-first approach reduces setup time and simplifies experimentation. It is often the fastest route to validation.
Self-hosted models or deeper customization demand more engineering effort but offer tighter control over inference behavior, cost curves, and compliance boundaries.
Here, the choice is less about convenience and more about how central AI is to your long-term roadmap.
Deciding Between Fine-Tuning vs. Prompt Engineering
Once the base model is selected, you must be crystal clear whether you want to adapt the model itself or optimize how you instruct it.
Many teams default to fine-tuning when outputs feel inconsistent. But if you want to solve issues faster (and at lower cost), it’s a recommended practice to combine structured prompt engineering with strong retrieval logic.

RAG and Vector Database Integration
Without retrieval, an LLM operates with limited awareness of your proprietary data. That gap becomes obvious in enterprise deployments.
Integrating a memory layer backed by a vector database, such as Pinecone, FAISS, or Weaviate, supports the RAG architecture. Embeddings convert documents into searchable representations, allowing the model to retrieve relevant context before generating a response.
Note: Context control is often the difference between a demo and a dependable system.
2. Tool Integration Layer – Extending the Agent’s Capabilities
The Tool Integration Layer determines what your AI agent can do beyond language processing. It connects the core LLM to external systems, APIs, and enterprise applications. It allows the agent to act on data, trigger workflows, and use specialized services.
Decisions that you make here affect your AI agent infrastructure, multi-agent coordination, and how well the system scales in production.
Identifying External Tools & APIs
You must have a clear picture of which services the agent interacts with because every API, microservice, or external data source adds capability and potential complexity.
What should you do?
- Define must-have integrations early to prevent later bottlenecks.
- Include enterprise SaaS tools, internal databases, and automation endpoints.
- Evaluate vendor reliability and API maturity before inclusion.
Designing Secure Integration Pipelines
Connecting systems introduces risk. Secure pipelines ensure that data flows correctly without exposing sensitive information or violating compliance standards.
What should you do?
- Monitor API health to prevent prolonged failures.
- Ensure connections comply with SOC 2, GDPR, or enterprise governance policies.
- Use encryption, token-based authentication, and rate-limiting to protect API calls.
Optimizing Tool Orchestration
Once tools are integrated securely, orchestrate them efficiently. Decide which tasks the agent handles natively and which are delegated to external systems. This keeps the system responsive and predictable.
What should you do?
- Use workflow engines to manage task dependencies across tools.
- Route high-frequency calls through lightweight pipelines to reduce latency.
- Implement logging for traceability and debugging across integrated systems.
3. Memory Layer – Context Persistence for Multi-Turn Reasoning
The Memory Layer determines how your AI agent remembers interactions, understands context, and grounds responses in enterprise knowledge. Getting this wrong leads to inconsistent outputs, broken workflows, and scaling headaches.
Below are a few things you should focus on:
Picking the Right Storage
Imagine an agent answering thousands of queries per minute across multiple products. The storage system must deliver context in milliseconds. As vector databases vary in speed, indexing methods, and integration complexity, you must choose them carefully.
Consider:
- Evaluating storage based on query volume and latency tolerance
- Assessing scalability for growth across multiple agents
- Factoring in integration with your existing AI agent infrastructure
Pro Tip: Align storage choice with expected traffic, memory growth, and latency targets to prevent costly slowdowns.
Session Memory vs. Long-Term Knowledge
Session memory supports high-frequency, short-lived interactions, whereas long-term memory retains strategic information and recurring patterns. This distinction affects how your AI agent handles multi-agent operations and complex reasoning tasks.
You must balance both of these to ensure the AI agent responds contextually without bloating storage or slowing inference.
Pro Tip: Misaligned memory can spike retrieval costs or confuse multi-agent workflows. Consider structuring memory based on lifespan to keep the agent responsive and accurate.
Efficient Context Retrieval
Even well-stored data is useless if retrieval is slow or irrelevant. When you use embeddings and RAG architecture, the system pulls the right context. This improves response quality and keeps latency low.
Without contextual retrieval, a multi-agent orchestration system may execute conflicting actions because one agent lacks the necessary context.
How to avoid poor retrieval?
Fine-tuning retrieval strategies avoids this issue and ensures the AI agent infrastructure scales predictably.
4. Orchestration Layer – Coordinating Multiple Agents and Tasks
The Orchestration Layer defines how multiple agents, tools, and memory interact to deliver reliable outcomes at scale. Here, you’ll decide how tasks move across agents, how workflow engines bind components together, and how event-driven design maintains system responsiveness under load.
The choices you make here affect operational efficiency, fault tolerance, and the scalability of your AI agent infrastructure.
Task Routing
Effective task routing keeps your agents aligned and prevents conflicts. It’s about control without slowing down operations.
Key Considerations:
- Assign tasks based on agent expertise to reduce processing overhead
- Monitor task completion to avoid conflicts in multi-agent workflows
- Balance load dynamically to prevent bottlenecks
Workflow Engine Integration
Workflow engines bind your LLMs, memory, and external tools into a coherent pipeline. Proper integration prevents cascading failures and keeps high-frequency operations smooth.
Focus Areas:
- Embed checkpoints to validate outputs mid-flow
- Track dependencies for better predictability
- Use workflow logs to optimize orchestration over time
Event-Driven Scalability
An event-driven approach lets agents act asynchronously and respond to system changes without waiting for rigid schedules. This is crucial for enterprise-scale deployment.
Implementation Tips:
- Prioritize critical events to maintain efficiency
- Include fallback and retry logic for resilience
- Link triggers to business workflows to reduce wasted cycles
5. Infrastructure Layer – Deploying the System at Scale
AI agents only matter if they perform reliably in production. Poor deployment choices create cascading failures, slow inference, and ballooning GPU costs. This layer shows how to translate architecture into a scalable, resilient, and manageable system, directly impacting operational efficiency and business outcomes.
There are a few things that you must know about:
Choice of Deployment Model
Your decision on where and how to deploy an AI agent holds immense importance. The wrong model or hosting approach can create obstacles across multiple agents and workflows. Think in terms of Kubernetes deployment, containerized AI services, serverless AI architecture, and on-prem AI hosting.
Tips for choosing the right deployment model:
- Map each deployment option to regulatory, latency, and cost constraints
- Assess the existing enterprise AI architecture to avoid integration gaps
- Decide between hybrid and cloud-native AI deployment strategies based on workload predictability
Scaling and Performance Planning
AI performance is often misunderstood as raw speed. For multi-agent systems, this means predictable responsiveness, efficient GPU utilization, and the ability to handle peak loads without failure.
What should you do?
- Implement autoscaling AI services to match real-time inference demand
- Optimize GPU cost optimization to control cost without compromising throughput
- Track latency and throughput against SLAs to prevent bottlenecks
Operational Pipelines for Reliability
Even with the right deployment and scaling strategy, systems fail without repeatable pipelines. A mature CI/CD approach for AI systems ensures that every model, workflow, and update can roll out safely.
Tips for reliable pipelines:
- Embed AI model versioning and rollback processes to avoid recurring errors
- Build MLOps pipelines for traceability, reproducibility, and performance monitoring
- Include failover and recovery strategies to maintain availability under load
6. Security & Compliance Layer – Protecting and Governing Your Agents
As your AI agent architecture connects to APIs, memory layers, and orchestration logic, it stops being an isolated model and becomes part of your core infrastructure. This shift simultaneously increases opportunities and risk.
If this layer is weak, every other layer inherits that weakness. So we approach it the preferred way: define risk, contain it, then prove compliance.
Identifying Threats to AI Agents
Most enterprise failures are not dramatic breaches. They begin with small trust gaps inside prompts, retrieval, or tool access across your AI deployment architecture.
Primary Risk Vectors
- Prompt injection attacks that hijack instructions or misuse function calling
- Model poisoning through compromised training or embedding inputs
- Silent data leaks across logs, memory, or loosely scoped API integrations
In multi-agent setups built on tools such as LangChain, CrewAI, or AutoGen, a compromised path can ripple through the entire AI orchestration layer. Threat modeling has to assume lateral movement, not isolated failure.
Implementing Security Measures
Controls should be embedded into system design, not layered on after launch. Strong AI agent security is structural, not cosmetic.
Structural Controls
- Enforce data encryption at rest and secure transport across services
- Apply least-privilege access within a zero-trust architecture
- Gate tool execution with scoped credentials and strict rate limiting
We also recommend our clients add runtime validation inside the orchestration logic itself, including prompt injection detection at the workflow level. That shift moves protection closer to execution, where damage actually occurs.
Meeting Compliance Standards
Security contains risk. Compliance proves discipline. For any AI system architecture, governance must be operational.
Enterprise Alignment Anchors
- Embed traceable logging across agents and workflows
- Formalize AI governance policies tied to system behavior
- Align controls with GDPR for AI systems and SOC 2 compliance for AI
When regulatory requirements are reflected directly in system design, compliance no longer slows innovation but becomes a part of how the system runs.
7. Observability & Monitoring Layer – Ensuring Reliability in Production
Once agents are live, assumptions don’t matter; behavior does. This layer ensures your AI agent architecture performs consistently under real workloads, edge cases, and business pressure. Observability is about understanding the system, not just displaying metrics.
Comprehensive Logging & Tracing
You can’t control what you can’t see. Each decision, action, and tool call must be reconstructable.
What should you track?
- Prompts, function calling, and tool interactions
- Task flow across the AI orchestration layer
- Outputs delivered to users or systems
Teams that link logs to business events, not just model outputs, can identify hidden inefficiencies or workflow conflicts before they affect operations.
Monitoring Model Drift & Performance
Degraded performance rarely triggers alerts. It appears as slower responses, slight inaccuracies, or less relevant outputs.
Monitoring should cover:
- Latency and throughput under varying load
- Accuracy and relevance over time
- Early drift signals in memory or retrieval layers
Integrity Checks for Prompts and Responses
Logs show what happened. Monitoring shows trends. Integrity checks prevent hidden failures.
Focus areas:
- Detect anomalies in prompts and tool usage
- Runtime prompt injection detection
- Validate outputs before any external system action
In multi-agent workflows, a single unchecked prompt can ripple across the entire enterprise AI architecture, causing silent errors. Runtime checks act as a last line of defense.
Conclusion: API-Only Stack vs. Full Custom Stack
When you’re building custom AI agents, an understanding of each layer of the AI agent architecture is one part. The final consideration is the overall system approach. Should you go for an API-only stack or a full custom stack?
As an AI agent development company that has helped multiple SMBs, we suggest that you shouldn’t just consider speed to market. The right choice depends on your business priorities, compliance requirements, and long-term AI strategy.
For instance, if your goal is to move faster, it’s suitable to use a provider API. But if you want to gain control, flexibility, and long-term scalability across LLM architecture design, agent orchestration, and workflow engine integration, a full custom stack is the right choice.
We’ve shared an expanded view of how each stack compares based on critical features in the following table:
| Feature/Consideration | API-Only Stack | Full Custom Stack |
|---|---|---|
| Model Control | Limited (vendor API) | Full (self-hosted/fine-tuning) |
| Latency & Throughput | Dependent on provider | Optimized for own infra |
| Cost | Pay-per-use | Higher upfront, scalable long-term |
| Tool Integration | Manual or limited | Full orchestration possible |
| Security & Compliance | Vendor responsibility | Fully controllable |
| Customization | Limited prompts | Full tuning & RAG integration |
| Maintenance | Minimal | Requires DevOps/MLOps effort |
Frequently Asked Questions (FAQs)
How To Deploy AI Agents In Production?
Production deployment starts with a stable AI deployment pipeline and controlled rollout. Consider focusing on:
Secure API communication and access control
Rate limiting and failover strategy
Performance validation before scaling
Because smooth coordination between development and operations teams is essential to ensure stability and predictable uptime, businesses often require expert DevOps consulting.
What Infrastructure Is Required For AI Agents?
A modular AI agent architecture relies on a hybrid infrastructure that combines Kubernetes or serverless platforms with secure API integrations and external data connectors. Embeddings storage supports RAG retrieval and long-term memory. Planning this setup carefully also helps manage the cost of building AI agent systems while maintaining performance, fault tolerance, and secure AI operations.
What Is RAG Architecture?
RAG architecture combines retrieval from vector stores with LLM reasoning to ground responses in relevant data. It enhances accuracy, reduces hallucinations, and makes multi-step reasoning across tools reliable for enterprise workflows.
Is Kubernetes Required For AI Deployment?
Kubernetes is not mandatory but offers reliable container orchestration, high-availability architecture, and scaling capabilities for complex multi-agent workflows. Smaller deployments can utilize serverless platforms with proper monitoring and secure AI deployment practices.
How To Monitor AI Agents In Production?
Monitoring AI agents in production requires both structured observation and the right tooling.
Self-Monitoring:
Track prompts, tool calls, and API interactions
Watch latency, throughput, and response accuracy
Detect subtle changes in outputs or memory retrieval
Recommended Tools:
Prometheus – metrics collection
Grafana – dashboards and alerts
Weights & Biases – performance tracking
ELK Stack – logging and tracing
This approach ensures consistent performance, model drift detection, and a reliable enterprise-grade AI deployment pipeline.
Download the AI Agent Architecture Blueprint to evaluate your current architecture and identify production gaps.