
Ever wondered how AI can generate text that feels almost human and perfectly fits your domain?
Interestingly, the global AI text generator market was valued at USD 425 million in 2023 and is projected to grow at a compound annual growth rate (CAGR) of 18% from 2023 to 2032, reaching USD 1,808 million by 2032. This surge, therefore, highlights the increasing demand for AI-driven content generation across industries.
Moreover, Hugging Face provides a well-supported ecosystem for working with causal language models (CLMs), offering tools like the Transformers library for model implementation, the Datasets library for data handling, and the speed-up library for efficient training. These resources, consequently, help developers to fine-tune pre-trained models, adapting them to specific tasks and domains.
Furthermore, fine-tuning involves adapting a pre-trained model to a new dataset, allowing it to learn the nuances of language patterns and terminologies.
As a result, this process improves the model’s performance on specialized tasks, making it more effective for applications such as chatbots, content generation, and domain-specific assistants.
In this blog, we will explore the fundamentals of causal language models, step-by-step fine-tuning with Hugging Face, and best practices for deploying your models.
Now, it’s time to explore!
What Are Causal Language Models (CLMs)?
Causal language modeling is the foundation of many modern text generation models. These models predict the next word in a sequence based on all previous words, making them a type of autoregressive language model. They read text from left to right, learning patterns that help them generate coherent and contextually accurate content.
Table of Contents
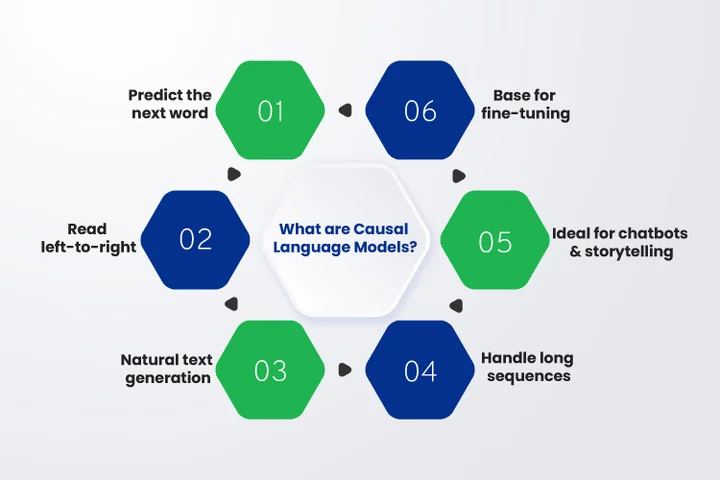
Unlike masked language models, which predict missing words within a sentence, causal language models focus entirely on predicting the next token. This design makes them especially effective for tasks such as dialogue generation, story writing, and domain-specific assistants, where continuity and flow matter.
Additionally, causal language models are at the core of well-known architectures like GPT, GPT-Neo, and LLaMA. These models have been trained on vast amounts of text, giving developers a strong starting point for building custom AI applications.
Why are Casual Language Models Important for Text Generation?
Teams can develop tools that grasp industry-specific terms or emulate a company’s writing style by fine-tuning causal language models.
Here are the reasons why causal language models are important for text generation models:
- Generating fluent and natural-sounding text outputs.
- Handling long sequences effectively for improved context understanding.
- Supporting applications like summarization, code generation, and content creation.
- Providing a solid base for training language models on specialized datasets.
Furthermore, these capabilities make causal language models a powerful choice for businesses and developers looking to build innovative solutions. Now that their role in text generation models is clear, the next step is to examine how model fine-tuning improves their performance for unique use cases.
Tired of generic AI that misses your industry’s voice? Our experts fine-tune models to match your domain and deliver results that matter.
What is a Fine-Tuning Model, and When Should It Be Used?
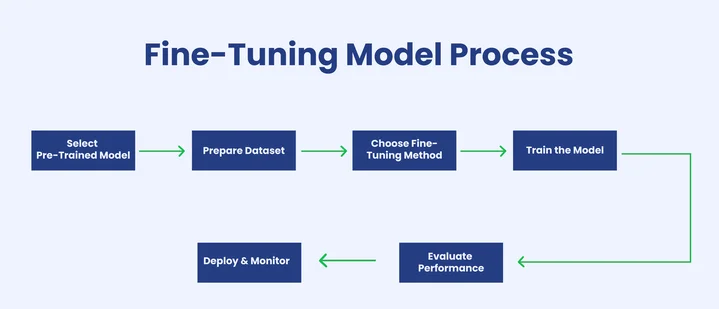
Model fine-tuning means adapting a pre-trained model to a new goal or dataset. Instead of building a model from zero, teams adjust an existing one so it learns a task that matches their needs. This approach saves time and computation while keeping high quality.
Additionally, model fine-tuning is essential for developers who work with training language models for domain-specific data. It allows custom AI applications to speak the language of a business, handle technical terms, or follow a chosen writing style.
Furthermore, there are different ways to apply fine-tuning causal language models. Full fine-tuning updates every weight in the model. Lighter methods such as LoRA, adapter tuning, or prompt tuning update only small parts, which lowers cost and training time.
What are Hugging Face Transformers, and How Do They Support Custom AI Apps?
Have you ever wondered how AI applications can generate text that feels almost human?
Hugging Face Transformers are at the heart of this capability. They are a collection of pre-trained text generation models designed to simplify training language models for various tasks, from chatbots to summarization tools.
However, Hugging Face Transformers provides developers with a flexible framework to build custom AI applications without starting from scratch. Instead of training a model entirely on your own data, you can fine-tune existing models, making them adapt to your specific requirements.
This approach saves both time and computational resources while producing highly accurate results. The Hugging Face ecosystem includes several key features that support developers:
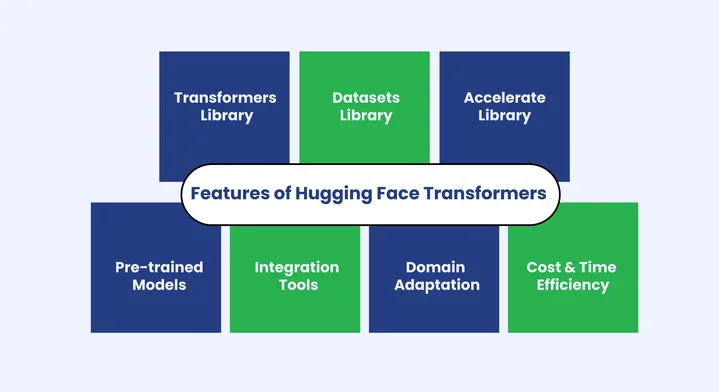
- Transformers library: Provides access to pre-trained models like GPT, GPT-Neo, and LLaMA for causal language modeling and other autoregressive language models.
- Datasets library: Simplifies loading, cleaning, and managing data for model training and evaluation.
- Accelerate library: Optimizes model training across different hardware setups, including GPUs and TPUs.
- Pre-trained models: Offers proven architectures that can be fine-tuned quickly for custom AI applications, reducing time-to-deployment.
- Direct integration: Fine-tuned models can be easily connected to applications for tasks such as text generation, summarization, and question answering.
Furthermore, Hugging Face Transformers enable a smooth connection between model training and deployment. Once a model is fine-tuned, it can be directly integrated into custom AI applications, supporting interactive features and domain-specific tasks.
We now go over how model fine-tuning supports custom AI and when it becomes the best option. It is most useful in situations like:
- Adapting pre-trained models such as GPT, GPT-Neo, or LLaMA for specific industry tasks.
- Improving accuracy on specialized datasets where generic models underperform.
- Reducing training costs by adjusting only parts of the model instead of building one from scratch.
- Creating custom AI applications for summarization, question answering, or domain-specific text generation.
These points show how model fine-tuning lets teams achieve precise outcomes with fewer resources. The next step is to prepare data correctly, which greatly affects training quality.
Now that the basics of model fine-tuning are clear, the next step is to look at the steps of Fine-Tuning CLMs with Hugging Face.
How Can You Fine-Tune CLMs with Hugging Face Step by Step?
Fine-tuning causal language models with Hugging Face Transformers follows a clear sequence of steps that simplifies the training process for custom AI applications. This approach helps teams adapt pre-trained text generation models to their own data while saving time and compute resources.
Now, we discuss the essential steps that guide this process in a structured way for successful fine-tuning of causal language models.
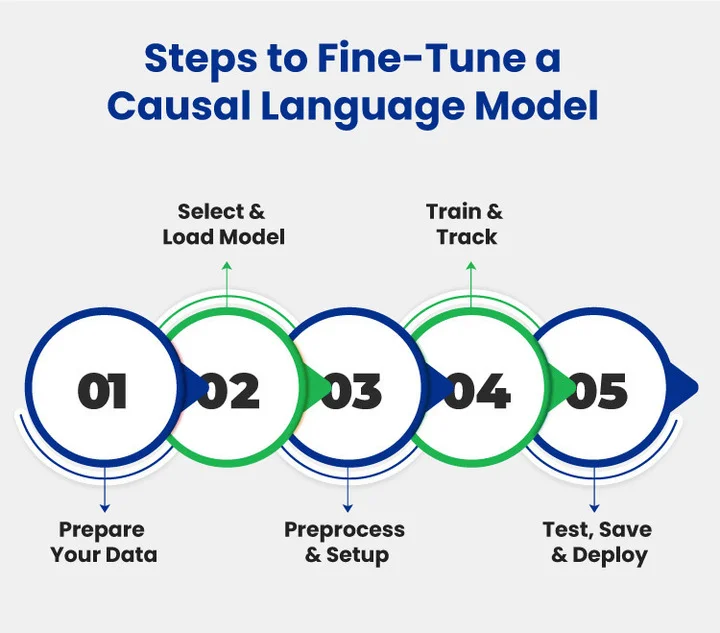
Step 1: Prepare Your Dataset
Your model will only be as good as the data you feed it. Before fine-tuning, assemble and clean a domain-specific corpus, then load it into Hugging Face’s datasets library.
- Collect domain-specific text: e.g., support chats, technical docs, and articles.
- Clean & split: normalize encoding, remove duplicates, strip sensitive data, and split into train/validation sets.
- Load with
datasets: makes shuffling, batching, and streaming easy for large corpora.
Here’s a minimal example:
from datasets import load_dataset
# Example: load a local CSV and split into train/validation
dataset = load_dataset('csv', data_files='my_domain_data.csv', split='train')
dataset = dataset.train_test_split(test_size=0.1)
train_ds = dataset['train']
val_ds = dataset['test']
print(train_ds[0]) # inspect a sample
How Does This Code Work?
After setting up your dataset file, this snippet loads it into a Hugging Face Dataset object with load_dataset and then uses .train_test_split() to automatically divide it into training and validation sets. You’re left with train_ds and val_ds, ready for tokenization in the next step.
Step 2: Choose and Load a Pre-Trained Model
Once your dataset is ready, pick a causal language model that’s closest to your use case (GPT-2, GPT-Neo, LLaMA, etc.). Use Hugging Face’s transformers library to load both the model and its tokenizer.
- Select a model: smaller models (like GPT-2) for quick experiments, larger ones (like EleutherAI/gpt-neo-1.3B) for more capacity.
- Load model + tokenizer: they must match to ensure correct tokenization.
- Check the config: max sequence length, special tokens, etc., before training.
For Example:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "EleutherAI/gpt-neo-1.3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
print(tokenizer.decode(tokenizer.encode("Hello Hugging Face!")[:10]))
How Does This Code Work?
This snippet loads a pre-trained model and its corresponding tokenizer from Hugging Face. The tokenizer converts text into token IDs that the model can understand, while the model itself is ready for fine-tuning on your data. After running this, you have both the model and tokenizer aligned and ready for the next training step.
Step 3: Set Up Training & Preprocessing
With your dataset and model ready, the next step is to prepare everything for training. This involves setting up your environment, tokenizing your data, and creating a data collator for causal language modeling.
- Environment setup: Make sure
transformers,datasets, andaccelerateare installed.Acceleratehelps run training efficiently on GPUs or TPUs. - Tokenization: Convert text into token IDs that the model can understand. This includes batching and padding sequences.
- Data collator: For causal language modeling, the data collator dynamically pads sequences and prepares input-target pairs for training.
For Example:
from transformers import DataCollatorForLanguageModeling
# Tokenize the dataset
def tokenize(batch):
return tokenizer(batch['text'], padding=True, truncation=True)
train_ds = train_ds.map(tokenize, batched=True)
val_ds = val_ds.map(tokenize, batched=True)
# Create a data collator for causal language modeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
How Does This Code Works
This snippet tokenizes each text sample in your training and validation datasets using the tokenizer aligned with your model. The DataCollatorForLanguageModeling then dynamically pads sequences and prepares them as input-target pairs for causal language modeling. Proper preprocessing ensures your model trains efficiently and handles text sequences correctly.
Step 4: Fine-Tune and Monitor
Now that your dataset is tokenized and your model is ready, it’s time to fine-tune. Hugging Face’s Trainer API simplifies the process by combining the model, dataset, tokenizer, and data collator into a single training workflow.
For Example:
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
overwrite_output_dir=True,
num_train_epochs=3,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
evaluation_strategy="steps",
save_steps=500,
logging_steps=100,
learning_rate=5e-5
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_ds,
eval_dataset=val_ds,
tokenizer=tokenizer,
data_collator=data_collator,
)
trainer.train()
How Does This Code Work?
This snippet sets up TrainingArguments to define the number of epochs, batch sizes, logging, and evaluation frequency. The Trainer object then combines the model, tokenizer, datasets, and data collator to run the training loop. Calling trainer.train() starts fine-tuning while automatically logging metrics and saving checkpoints, making it easy to monitor progress and adjust parameters if needed.
Step 5: Evaluate, Save & Deploy
Fine-tuning your model is complete, but the work isn’t over yet. Before using it in a real application, it performs well, can be saved safely, and is ready for deployment. This step transforms your trained model into a reliable tool for real-world tasks.
Now, let’s break down the key actions required to make your model production-ready.
Evaluate the model
- Test your fine-tuned model on the validation dataset.
- Check metrics like loss or task-specific scores.
- Generate sample outputs to ensure it behaves as expected.
Save the model
- Keep a copy of the model and tokenizer so they can be reloaded later.
- Optionally, push the fine-tuned model to the Hugging Face Hub for versioning or sharing.
Deploy the model
- Integrate the model into your application for real-time use.
- Use frameworks like FastAPI, Hugging Face Inference API, or TorchServe for larger-scale deployments.
Key point: This step ensures your model is usable, reusable, and ready for real-world applications.
Frequently Asked Questions (FAQs)
2. How Much Data Do You Need To Fine-Tune A Causal Language Model?
It depends on your model and goals:
- Small models (GPT-2): A few thousand examples.
- Large models (GPT-Neo, LLaMA): Tens of thousands of examples.
Focus on clean, relevant data, and quality matters more than quantity.
3. Can You Deploy a Fine-Tuned Model Directly Into Production?
Yes, once your model is evaluated and performs well on validation data, it can be deployed using frameworks like FastAPI, TorchServe, or the Hugging Face Inference API. Proper evaluation and testing ensure it behaves reliably in real-world applications.
Wrapping Up: Fine-Tuning Causal Language Models with Hugging Face
In this blog post, we discuss how fine-tuning causal language models opens up powerful possibilities for building AI applications that understand your domain and generate highly relevant content. Naturally, implementing these models effectively requires not just data preparation and training but also expert guidance to deploy them efficiently and ensure they perform reliably.
If you want professional support to transform your fine-tuned models into actionable solutions, AI Consulting services can help you plan, implement, and optimize your AI initiatives.
Once your model is ready, you can integrate it into applications that enhance user experience, automate workflows, or provide smart insights tailored to your business needs.
You can solve your most pressing AI problems by confidently transitioning from experimentation to real-world implementation by combining the step-by-step knowledge from this guide with professional AI consulting.
Still using generic AI? Fine-tune models can boost accuracy by up to 80% and cut wasted effort.